
MM2 - Session 2 - Ethics of Marketing Research

In the second session of marketing research we delved right into the Amazon Shopper Panel: Paying Customers for Their Data case by: Eva Ascarza and Ayelet Israeli. The short case discusses how Amazon’s new consumer panel program seeks to understand the behaviour of its users outside of Amazon. At its heart, the case seeks to understand the value of customers’ data and various regulations that are currently in place to protect consumers.
However, we take a slightly different approach than what the authors take. In short, we ask, what is the value of every bit of data that gets added to a dataset?, to what extent can companies use such data?, and where do you draw the line? There is no denying that online giants like Google, Amazon, Apple and Facebook today control several digital assets. These assets may be combined to form an ecosystem of mutually complementary services. For example, Google offers dozens of services (product page screenshot found below) such as Agenda (that’s what google calendar is now called), Android, Scholar, Meet, Drive, Search and Fit.

Each of these services collects plenty of data about our activities. While this data can be individually very powerful, the utility of the data to a marketer increases manifold when the data is aggregated together. Let me illustrate with an example. Google could in theory use a combination of your current locations (sourced through Maps), the music you are listening to (sourced from Youtube Music) and Pulse rate (sourced through Google fit) to provide you with advertisements and offers on your phone’s Google app. Let’s say you are happy and listening to some romantic tracks in a mall, Google may try to link you to advertisers seeking to target you. Google argument (as seen in the video of Google CEO Sundar Pichai testifying in the US Congress back in 2018- found below) is that this helps improve the product that they offer consumers.
While this may be true, it is important to contrast this stand with Apple Inc’s. Apple maintains that it may not be required for tech firms to retain invasive tracking databases of their customers' locations, and other sensitive data. The answer may lie in the fact that unlike Google, Apple makes most of its revenue from the sale of Hardware. Also note that Pichai explicitly states that Google tries to “ minimise the data we need to provide the service back to (our) users” . The key word here is ‘minimise’. It is important to how understand how much is actually enough. With decreasing costs of storing data and ease of collecting data in recent years, it is easy to see why many firms would want to collect as much data as possible. This very idea was featured on the cover of the Economist magazine not too long ago (6 May edition, 2017, cover found below).

While the privacy debate continues to rage on, another interesting issue to note here is the the issue of competition. More specifically, anti-competition. Should Amazon collect the data of consumers’ non Amazon purchases, what would they possibly do with it? To answer this question, we should first examine the structure of the data that Amazon is likely to collect. It is easy to imagine how a simple scan of receipts from third party brick and mortar sellers could divulge
- What products were purchased
- Bill value, and volume of goods bought
- Time of the purchase
- Location of the retailer (from the address)
- The amount of time spent in the retail establishment
- The distance of the customer from the retail establishment
- The frequency with which the customer visits the establishment (remember, once you upload one receipt, this data can always be collected)
- The frequency with which other consumers visit these retail establishments
- A comprehensive list of the products these frequented retailers stock, their prices and business hours.
And the list can go on. With this kind of rich data, Amazon could theoretically offer all customers around a certain competitive retail establishment, offer them discounts of key product categories for some time, and effectively nudge consumers to stop frequenting an establishment. This may seem like a very good tactic from Amazon’s perspective, but this can have extremely bad consequences for third party retailers dotted across the retail scape and consumers.
The third dimension that we need to explore here is the issue of data security. Well, let’s assume the data is used in the most ethical way possible and does not really get used for anticompetitive activities. What assurance does one have that the data cannot be stolen from such tech companies. Found below is a beautiful graphic from information is beautiful that showcases how many severe data breaches have been over the past years.
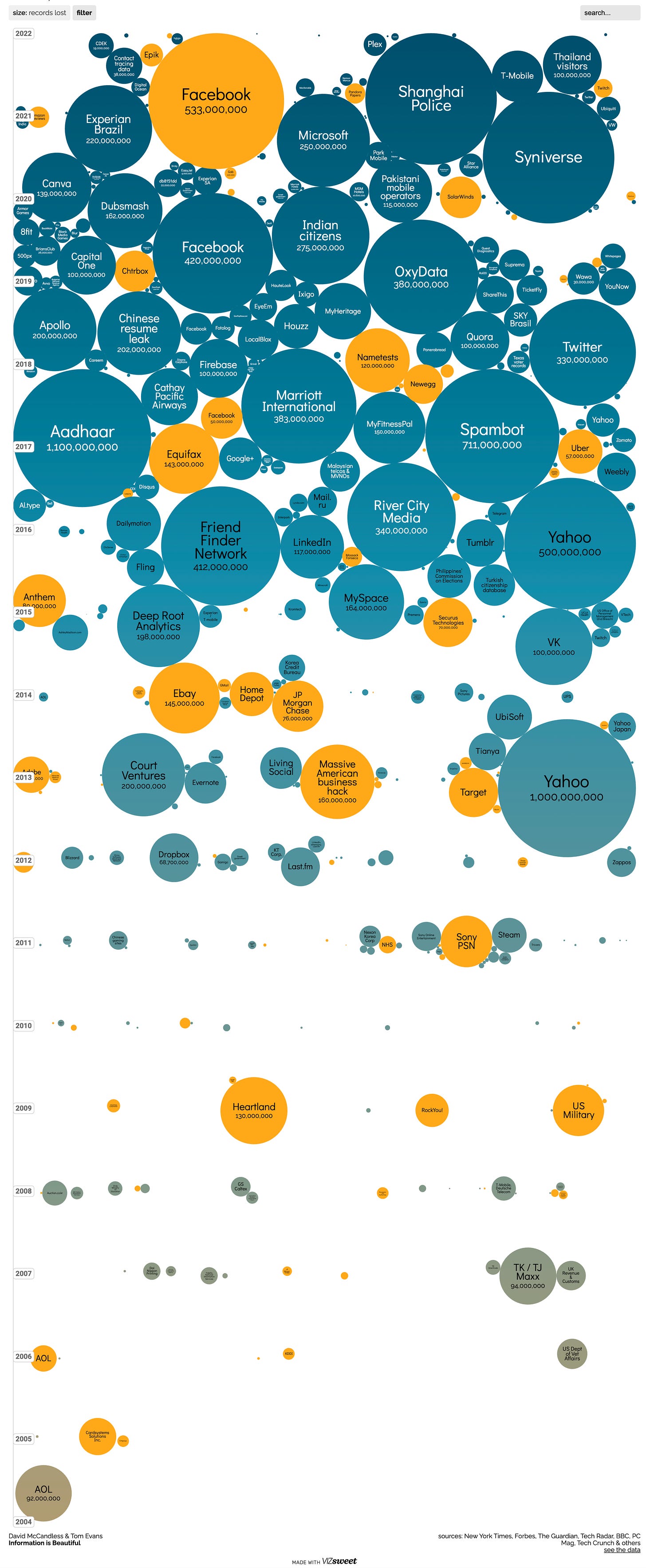
These three factors are clearly ideas that need to be in the back of every marketer’s mind. Considering all of you will be joining firms very soon and working in various positions, it may be critical for you to understand the severity of the right data can do in the wrong hands.
Having said that, I hope you enjoy exploring the creeks and cervices of marketing research over the duration of this course. As always, If you would like to talk about some ideas, you may reach out to me any time.
Let’s meet in class soon!
And wish you a very very very Happy Diwali !!
